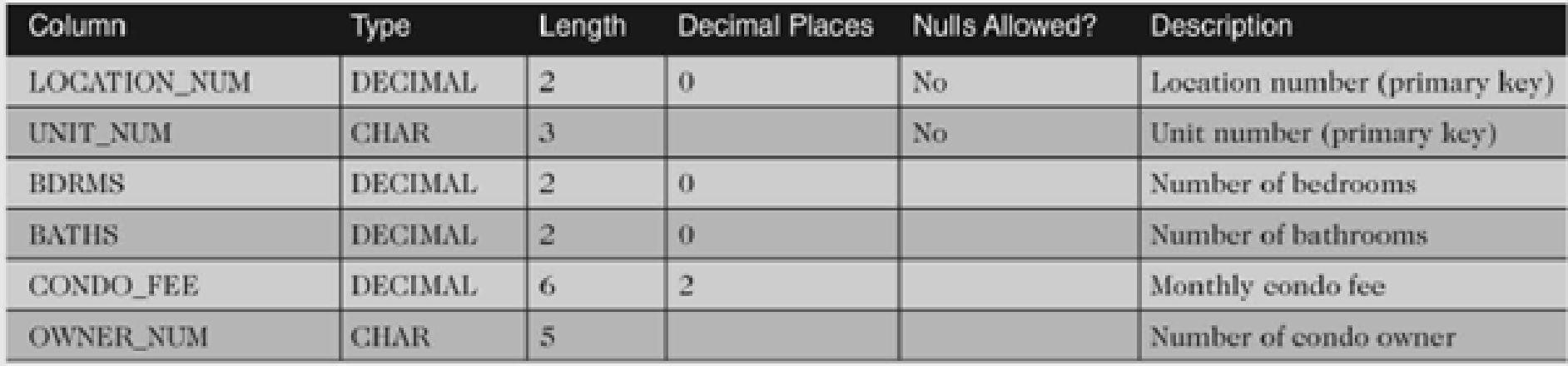
Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause near the end of the SQL statement. Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions. Aggregate_expression This is the column or expression that the aggregate_function will be used on. Tables The tables that you wish to retrieve records from. There must be at least one table listed in the FROM clause.

These are the conditions for the records to be selected. HAVING condition This is a further condition applied only to the aggregated results to restrict the groups of returned rows. Only those groups whose condition evaluates to TRUE will be included in the result set. The GROUP BY clause groups together rows in a table with non-distinct values for the expression in the GROUP BY clause.

For multiple rows in the source table with non-distinct values for expression, theGROUP BY clause produces a single combined row. GROUP BY is commonly used when aggregate functions are present in the SELECT list, or to eliminate redundancy in the output. Pluck can be used to query single or multiple columns from the underlying table of a model.
It accepts a list of column names as an argument and returns an array of values of the specified columns with the corresponding data type. Once the rows are divided into groups, the aggregate functions are applied in order to return just one value per group. It is better to identify each summary row by including the GROUP BY clause in the query resulst. All columns other than those listed in the GROUP BY clause must have an aggregate function applied to them.
The implementation of window function features by vendors of relational databases and SQL engines differs wildly. Most databases support at least some flavour of window functions. However, when we take a closer look it becomes clear that most vendors only implement a subset of the standard. Only Oracle, DB2, Spark/Hive, and Google Big Query fully implement this feature. More recently, vendors have added new extensions to the standard, e.g. array aggregation functions.

User-defined aggregate functions that can be used in window functions are another extremely powerful feature. A SELECT statement retrieves zero or more rows from one or more database tables or database views. In most applications, SELECT is the most commonly used data manipulation language command. As SQL is a declarative programming language, SELECT queries specify a result set, but do not specify how to calculate it. The database translates the query into a "query plan" which may vary between executions, database versions and database software.
This functionality is called the "query optimizer" as it is responsible for finding the best possible execution plan for the query, within applicable constraints. An outer join will combine rows from different tables even if the join condition is not met. Every row in the left table is returned in the result set, and if the join condition is not met, then NULL values are used to fill in the columns from the right table. The GROUP BY clause is a SQL command that is used to group rows that have the same values. Optionally it is used in conjunction with aggregate functions to produce summary reports from the database. The optional RETURNING clause causes UPDATE to compute and return value based on each row actually updated.
Any expression using the table's columns, and/or columns of other tables mentioned in FROM, can be computed. The new (post-update) values of the table's columns are used. The syntax of the RETURNING list is identical to that of the output list of SELECT. When you have more complex queries that involve JOIN and GROUPBY operations, you can project on joined fields as well and apply functions to groups of data. The syntax of the select new keyword is flexible enough to accommodate an explicit property naming.

In the JOIN example shown earlier, you explicitly set the name of the column that reports the total number of orders for a customer to OrderCount. While the first query is not needed, I've used it to show what it will return. I did that because this is what the second query counts. The ORDER BY clause specifies a column or expression as the sort criterion for the result set.

If an ORDER BY clause is not present, the order of the results of a query is not defined. Column aliases from a FROM clause or SELECT list are allowed. If a query contains aliases in the SELECT clause, those aliases override names in the corresponding FROM clause. SQL aggregate functions provide information about a database's data. AVG, for example, returns the average of a database column's values.

By setting the LoadOptions property, you specify a static fetch plan that tells the runtime to load all customer information at the same time order information is loaded. Based on this, the LINQ to SQL engine can optimize the query and retrieve all data in a single statement. Listing 4 shows the SQL Server Profiler detail information for the exec sp_executesql query after the code modification.
The query now includes a LEFT OUTER JOIN that loads orders and related customers in a single step. You may think that after running the first query to grab all matching records in the Orders table, you're fine and can work safely and effectively with any selected object. As Figure 2 shows, many additional queries actually hit the SQL Server database.

Let's expand on one of them, the exec sp_executesql statement, in Listing 3. The SQL standard requires that HAVING must reference only columns in the GROUP BYclause or columns used in aggregate functions. However, MySQL supports an extension to this behavior, and permits HAVING to refer to columns in the SELECT list and columns in outer subqueries as well. A subquery with a recursive table reference cannot invoke aggregate functions.

The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions. Prior to the introduction of MySQL 5.5 in December 2009, MyISAM was the default storage engine for MySQL relational database management system versions. It's based on the older ISAM code, but it comes with a lot of extra features. The file names start with the table name and end with an extension that indicates the file type. The table definition is stored in a.frm file, however this file is not part of the MyISAM engine; instead, it is part of the server.

If you lose your index file, you may always restore it by recreating indexes. As a result, SQL creates a new table with a duplicate structure to accept the fetched entries, but nothing is stored into the new table since the WHERE clause is active. The INSERT statement uses the data returned from the subquery to insert into another table. The selected data in the subquery can be modified with any of the character, date or number functions.

It goes without saying that many SQL Server queries are easier to formulate with words than with T-SQL. The more you master the SQL Server language, the easier it could be for you to express queries directly in T-SQL. However, for the vast majority of developers working on data-access components, finding a T-SQL counterpart for the following query could be difficult. Let's consider a query that returns for each customer the total number of orders he placed in given timeframe.

The query clearly involves a join between customers and orders. Listing 5 shows how you'd write it using a LINQ to SQL object model and the LINQ query language. Will result in the elements from the column C1 of all the rows of the table being shown. This is similar to a projection in relational algebra, except that in the general case, the result may contain duplicate rows. This is also known as a Vertical Partition in some database terms, restricting query output to view only specified fields or columns. The GROUP BY clause projects rows having common values into a smaller set of rows.

GROUP BY is often used in conjunction with SQL aggregation functions or to eliminate duplicate rows from a result set. While these values don't have any practical use, this shows the power of aggregate functions. The INTERSECT operator returns rows that are found in the result sets of both the left and right input queries.

Unlike EXCEPT, the positioning of the input queries does not matter. Set operators combine results from two or more input queries into a single result set. You must specify ALL or DISTINCT; if you specify ALL, then all rows are retained. The USING clause requires a column list of one or more columns which occur in both input tables. It performs an equality comparison on that column, and the rows meet the join condition if the equality comparison returns TRUE. SELECT AS STRUCT can be used in a scalar or array subquery to produce a single STRUCT type grouping multiple values together.

Scalar and array subqueries are normally not allowed to return multiple columns, but can return a single column with STRUCT type. The GROUP BY clause divides the rows returned from the SELECTstatement into groups. For each group, you can apply an aggregate function e.g.,SUM() to calculate the sum of items or COUNT()to get the number of items in the groups.

The GROUP BY statement is often used with aggregate functions (COUNT(),MAX(),MIN(), SUM(),AVG()) to group the result-set by one or more columns. SQL clause helps to limit the result set by providing a condition to the query. A clause helps to filter the rows from the entire set of records. A SELECT command gets zero or more rows from one or more database tables or views. The most frequent data manipulation language command is SELECT in most applications. SELECT queries define a result set, but not how to calculate it, because SQL is a declarative programming language.

A relational database management system is a type of database management system that stores data in a row-based table structure that links related data components. An RDBMS contains functions that ensure the data's security, accuracy, integrity, and consistency. This is not the same as the file storage utilized by a database management system. LINQ to SQL doesn't work with databases other than SQL Server.

So, unlike ADO.NET or industry-standard object-relational mapping tools, you can't use LINQ to SQL to work with, say, Oracle databases. LINQ to SQL doesn't attempt to push an alternate route and doesn't aim to replace T-SQL; it simply offers a higher-level set of query tools for developers to leverage. LINQ to SQL is essentially a more modern tool to generate T-SQL dynamically based on the current configuration of some business-specific objects. T-SQL operates on a set of tables, whereas LINQ to SQL operates on an object model created after the original set of tables.
In this article, I am giving some examples of SQL queries which is frequently asked when you go for a programming interview, having one or two year experience in this field. SELECT is the most common operation in SQL, called "the query". SELECT retrieves data from one or more tables, or expressions. Standard SELECT statements have no persistent effects on the database. Some non-standard implementations of SELECT can have persistent effects, such as the SELECT INTO syntax provided in some databases. The SQL SELECT statement returns a result set of records, from one or more tables.

SQL_BIG_RESULT or SQL_SMALL_RESULT can be used with GROUP BY or DISTINCT to tell the optimizer that the result set has many rows or is small, respectively. For SQL_BIG_RESULT, MySQL directly uses disk-based temporary tables if they are created, and prefers sorting to using a temporary table with a key on the GROUP BY elements. For SQL_SMALL_RESULT, MySQL uses in-memory temporary tables to store the resulting table instead of using sorting.

How Do You Write A Group By Query In Sql All tables referenced by the query block are locked when OF tbl_name is omitted. Consequently, using a locking clause without OF tbl_name in combination with another locking clause returns an error. Specifying the same table in multiple locking clauses returns an error. If an alias is specified as the table name in the SELECT statement, a locking clause may only use the alias. If the SELECT statement does not specify an alias explicitly, the locking clause may only specify the actual table name.

While all aggregate functions could be used without the GROUP BY clause, the whole point is to use the GROUP BY clause. That clause serves as the place where you'll define the condition on how to create a group. When the group is created, you'll calculate aggregated values.

This is the same model we've been using in a few past articles. I won't go into details, but rather mention that all 6 tables in the model contain data. Some of the records in tables are referenced in others, while some are not. E.g. we have countries without any related city, and we have cities without any related customers.
We'll comment on this in the article where it will be important. The result set always uses the supertypes of input types in corresponding columns, so paired columns must also have either the same data type or a common supertype. Because the UNNEST operator returns avalue table, you can alias UNNEST to define a range variable that you can reference elsewhere in the query. If you reference the range variable in the SELECTlist, the query returns a STRUCT containing all of the fields of the originalSTRUCT in the input table.

Query statements scan one or more tables or expressions and return the computed result rows. This topic describes the syntax for SQL queries in BigQuery. This iterative refinement will allow you to hone in on just the right SQL statement to retrieve the desired information. With jOOQ, stored procedures and stored functions are first-class citizens, if you chose them to be. The jOOQ code generator will generate a callable method for every routine.